
What no one tells you about GPU benchmarks
In several past roles I have spent time thinking about difficult numerical computing problems. Before joining Red Gate I was lucky enough to get to work on the problem of taking numerically intense C# code and generating CPU code at run-time.
Part and parcel of caring about performance is benchmarking. Benchmarking is an art. And like art it requires interpretation.
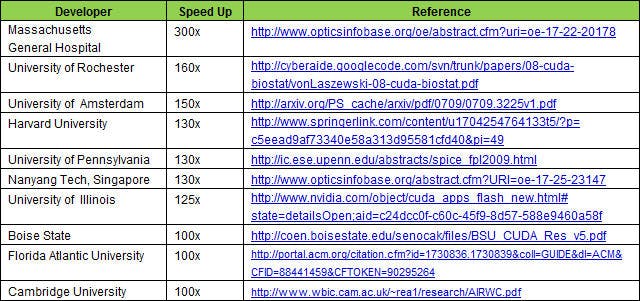
We will use a very simple example to highlight two effects you should be on the look out for. Multiplying a matrix by a vector is suitably simple for our purposes. In the real-world you should use a suitable library implementation. I have had considerable success with the Intel Math Kernal Library and Intel Integrated Performance Primitives. After all, this is not my day job and there are some very smart people out there who's job it is.
Example 1 - CPU
A straight-forward implementation will use two nested loops - effectively iterating over every element of the matrix. In C# this would look as follows.
for (int j = 0; j < dim; j++)
{
for (int i = 0; i < dim; i++)
{
vecOut[j] += matrix[i, j] * vecIn[j];
}
}
All timings which follow are for a square matrix of dimension 8092x8092. Which makes for a 256MB two-dimensional array.
Running a single iteration on my desktop machine turns in a time of 1,100ms. This is out first data point.
| Example | Running time (ms) |
|---|---|
| CPU 1 | 1,100 |
Example 2 - GPU
Let's take the same algorithm and port it to run on a GPU.
__global__ void multiplyKernel(float *c, const float *a, const float *b, const int size) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
c[index] = 0;
for (int j = 0; j < size; ++j)
c[index] += a[index * size + j] * b[index];
}
The language is CUDA which for our purposes you can think of as C with extensions. You will notice there is only one loop present. This is because this kernel is actually run 8092 times in parallel on the GPU so we do not need to have an explicit outer loop.
The calculation now takes approximately 5ms. That's a good 200x speed up right there!
| Example | Running time (ms) |
|---|---|
| CPU 1 | 1,100 |
| GPU 1 | 5 |
Example 4 - CPU revisited
We could stop there but we won't because I'm sure a number of alarms are going off in your head right now. A common objection at this point is that the CPU code is purely scalar so would benefit from being run in parallel across multiple CPU cores.
This is true but there is something else deeply wrong with the CPU implementation. It is particularly cache-unfriendly. The inner loop is iterating down each column of the matrix. This is unfortunate because in .NET two-dimensional arrays are stored in memory in row-major form. If instead we swap the the two loops we now iterate along the rows where elements are stored sequentially in memory. This means the next N elements will be pulled down in the same cache line saving us expensive cache misses.
for (int i = 0; i < dim; i++)
{
for (int j = 0; j < dim; j++)
{
vecOut[i] += matrix[i, j] * vecIn[i];
}
}
Simply swapping the order of the loops takes us down to 200ms. This is a nice example of the application of mechanical sympathy. Herb Sutter gives a great talk on machine architecture and modern memory hierarchy.
This also highlights the fact that looking at the big N behaviour of your algorithm does not necessarily tell you as much as you might hope. Always measure etc etc.
| Example | Running time (ms) |
|---|---|
| CPU 1 | 1,100 |
| GPU 1 | 5 |
| CPU 2 | 200 |
Example 4 - GPU revisited
Despite the gains we can expect to make by optimising our CPU implementation it still feels like a tall order to get down to times recorded for our GPU implementation.
Let's take a closer look at what we actually want to measure in our benchmark. So far we've done our best to time the computational aspect of the task (though in reality we're memory-bandwidth constrained). Is this a useful approach? Well, it depends what you want to do!
The elephant in the room is the fact that the GPU is a separate device which sits at the far end of the PCI-Express bus. Crucially this means transferring data to and from the GPU is comparatively expensive.
This means that for short running tasks it is often the case that the communication overhead renders using the GPU useless even if the actual work is much faster. For this reason it is important to keep data on the GPU whenever possible and get as much work done as possible before returning a result. The work I mentioned at the beginning would effectively batch up many C# operations to be run in one go on the GPU in order to amortise the communication cost.
Including the time spent transferring the data to and from the GPU we now get a time of 110ms. Not so different to our naive CPU approach.
| Example | Running time (ms) |
|---|---|
| CPU 1 | 1,100 |
| GPU 1 | 5 |
| CPU 2 | 200 |
| GPU 2 | 110 |
Wrap-up
The two things to always be aware of when evaluating and performing CPU/GPU benchmarks are:
- un-optimised CPU implementation
- not including data transfer time
Full source code for the examples: